
Java IO
- Input指从外部读入数据到内存,例如,把文件从磁盘读取到内存,从网络读取数据到内存等。
- Output把数据从内存输出的外部。
IO流是以byte为最小单位,是一种顺序读写数据的模式,特点是单向流动,因此在Java中InputStream代表输入字节流,OutputStream代表输出字节流。
如果读写的是字符,字符不止有ASCII字符,此时按照char读写更方便,这种流称为字符流。
Java提供了Reader和Writer表示字符流,传输的最新单位是char,本质上是一个自动编解码的InputSteam和OutputStream。
Java标准库还提供了同步IO包java.io,异步IO包java.nio。
File对象
java.io.File用来操作文件和目录。
FIle f = new File("/etc/passwd"); 路径可以是相对路径也可以是绝对路径。
getPath()返回构造方法传入的路径,getAbsolutePath()返回绝对路径,getCanonicalPath与绝对路径相似返回规范路径(正常路径)
1 | File f = new File("."); |

- File对象既可以表示文件也可以表示目录
- 构造File对象并不进行磁盘操作,只有调用其某些方法时,才进行磁盘操作
isDirectory()是否是一个目录boolean canRead()、boolean canWirete()、`boolean canExecute()是否可读可写可执行long length()文字字节大小list()``listFiles()列出目录下的文字和子目录名boolean mkdir()创建对象表示的目录boolean mkdirs可创建不存在的父目录的目录boolean delete()删除当前对象表示的目录
java.nio.file包还提供一个Path对象,该对象与File对象类似
1 | Path p1 = Paths.get(".", "project", "study"); // 构造一个Path对象 |
InputStream、OutputStream
####InputSteam
InputSteam(抽象类,并不是一个接口)
1
public absteact int read() throws IOException;
FileInputStream继承自InputStream- read方法会读取输入流的下一个字节,并返回表示字节表示的int值,如果返回-1表示读到末尾。
InputStream和OutputStream都实现了java.lang.AutoCloseable接口会自动finally语句并调用close()方法。
使用缓冲高效读取字节流,
InputStream提供两个重载方法支持读取int read(bytep[] b)读取若干个字节并填充到数组,返回读取的字节数int read(read[] b, int off. int len)指定byte[]数组的偏移量和最大填充数
1 | public void readFile() throws IOException { |
阻塞(需要等待read读完才能执行下面的其他操作)
可以对InoutSteam抽象类实现任意类
ByteArrayInputStream实际上是把一个byte[]数组在缓冲区变成一个InputStream- 该类可以向上转型方便调用如模拟数据等
1
2byte[] data = {333,44,555,66,777,89,10};
InputSteam input = new ByteArrayInputStream(data);
OutputStream
同InputSteam一样,OutputStream也是一个抽象类,其中一个重要的方法是
1 | public abstract void write(int b) throws IOException; |
该方法会写入一个字节到输出流,传入的int最低表示字节的部分(相当于b & 0xff)。
同时OutputStream需要一个缓冲区(由数组组成),默认写满缓冲区后自动调用flush()输出缓冲区内容。但即时聊天需要每次输入一句话后,调用flush()手动刷新。
- 同
InputSteam编译器会自动写入finally并调用close() - 同
InputSteamwrite()会阻塞 - 同
InputSteamByteArrayOutputStream可以在内存中模拟一个OutputStream
装饰器模式(Decorator)/Filter模式
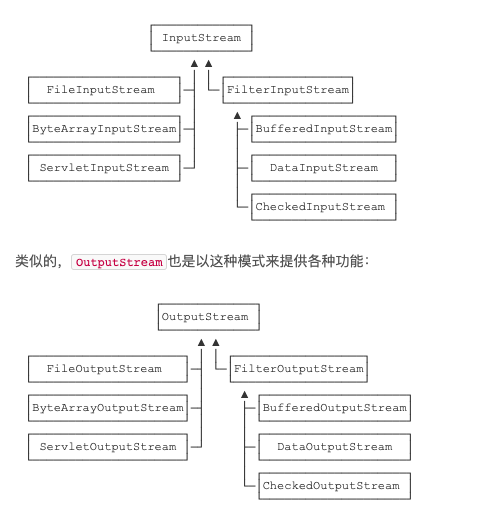
为了解决依赖继承会导致子类数量失控的问题,JDK将InputStream分为两大类:
- 直接提供数据的基础
FileInputStream、ByteArrayInputStream、ServletInputStream…
- 提供额外附加功能的
BufferInputStream、DigestInputStream…
当我们需要给一个基础InputStream附加各种功能时,我们先确定提供数据源的InputStream,比如FileInputStream
1 | InputStream file = new FileInputStream('test.gz'); |
紧接着,希望能通过缓冲区提供读取效率,使用BufferInputStream包装InputStream,得到的包装类型为BufferInputStream,但他仍旧是InputStream
1 | InputStream buffer = new BufferInputServer(file); |
最终希望读取gzip压缩数据,再使用GZIPInputStream
1 | InputStream data = new GZIPInputStream(buffer); |
不论如何,得到的对象都是InputStream,然后就可以通过InputStream直接饮用使用。
上述这种通过一个“基础”组件再叠加各种“附加”功能组件的模式,称之为Filter模式(或者装饰器模式:Decorator)
目的是为了通过较少的类实现各种功能的组合。
- 注意到在叠加多个
FilterInputStream,我们只需要持有最外层的InputStream,并且,当最外层的InputStream关闭时(在try(resource)块的结束处自动关闭),内层的InputStream的close()方法也会被自动调用,并最终调用到最核心的“基础”InputStream,因此不存在资源泄露。
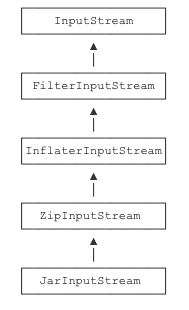
操作Zip
ZipInputStream就是一种装饰器,他可以直接读取zip包的内容。JarInputStream是派生自ZipInputStream,增加的是能直接读取jar文件里面的MANIFEST.MF文件。
读取zip包
1 | try (ZipInputStream zip = new ZipInputStream(new FileInputStream(...))) { |
写入压缩包
1 | try (ZipOutputStream zip = new ZipOutputStream(new FileOutputStream(...))) { |
读取classpath
- 把资源存储在classpath中可以避免文件路径依赖;
在classpath中的资源文件,路径总是以/开始,先获取当前的Class对象,然后调用getResourceAsStream()就可以从classpath读取任意资源文件:
1 | try(InputStream input = getClass.getResourceAsStream('/default.properties')){} |
没有这个资源将返回null
序列化与反序列化
序列化是指把一个Java对象变成二进制内容(byte[]数组),用以储存文件或者网络传输。反序列化正好相反。
要序列化对象,需先实现java.io.Serializable接口:
1 | public interface Serilizable{} //没有方法的空接口,也称为标记接口,目的仅仅是标记 |
序列化:
使用ObjectOutputStream把一个对象写入字节流
1 | ByteArrayOutputStream buffer = new ByteArrayOutputStream(); |
反序列化:
使用ObjectInputStream从字节流读取对象
1 | try (ObjectInputStream input = new ObjectInputStream(...)){ |
- 反序列化时,由JVM直接构造出Java对象,不调用构造方法,构造方法内部的代码,在反序列化时根本不可能执行。
Reader、Writer
Reader
Reader是Java的IO库提供的另一个输入流接口。和InputStream的区别是,InputStream是一个字节流,即以byte为单位读取,而Reader是一个字符流,即以char为单位读取。
读取方法和InputStream一样,读取方法public int read() throws IOException;读到末尾返回-1
FileReader是Reader的子类,为了避免乱码情况,在创建时指定编码
1 | Reader reader = new FileReader("src/read.txt", StandardCharsets.UTF_8); |
一次性读取若干字符到char数组int read(charp[] c)
CharArrayReader可以在内存中模拟一个Reader,它的作用实际上是把一个char[]数组变成一个Reader,这和ByteArrayInputStream非常类似StringReader
StringReader可以直接把String作为数据源,它和CharArrayReader几乎一样:1
2try (Reader reader = new StringReader("Hello")) {
}InputStreamReader(用以由InputStream转换Reader用)
- Reader
是带编码转换器的InputStream它把byte转换为char
- Reader
1 | try (Reader reader = new InputStreamReader(new FileInputStream("src/readme.txt"), "UTF-8")) { |
Write
Write是带编码转换器的OutputStream,把char转换为byte输出。
Writer是所有字符输出流的超类,它提供的方法主要有:- 写入一个字符(0~65535):
void write(int c); - 写入字符数组的所有字符:
void write(char[] c); - 写入String表示的所有字符:
void write(String s)。
- 写入一个字符(0~65535):
FileWrite和FileReader一样
CharArrayWriter和
ByteArrayOutputStream非常类似,构造缓冲区写入charStringWriter也是一个基于内存的Writer,它和CharArrayWriter类似。实际上,StringWriter在内部维护了一个StringBuffer,并对外提供了Writer接口除了
CharArrayWriter和StringWriter外,普通的Writer实际上是基于OutputStream构造的,它接收char,然后在内部自动转换成一个或多个byte,并写入OutputStream。因此,OutputStreamWriter就是一个将任意的OutputStream转换为Writer的转换器。
PrintStream和PrintWriter
PrintStream
PrintStream是一种FilterOutputStream,在OutputStream接口上,额外提供了一些写入各种数据的写法:
- 写入int,print(int); 写入boolean, print(boolean) …
- 写入Object:print(Object)相当于print(object.toString())
- 以及对应的println()会自动加上换行符
经常使用的System.out.println()实际上就是使用PrintStream打印各种数据,System.out是默认提供的PrintStream,表示标准输出。
PirntStream与OutputSteam相比不会抛出IOException。
PrintWriter
PrintStream 最终输出的总是byte数据,而PrintWriter则是拓然了Writer接口,它的print,println方法最终输出的是char数据,其他使用方法激活一模一样。